Segment Any Motion in Videos
🌟 Segmenting moving objects in videos without human annotations 🌟
CVPR 2025
Click the thumbnails below to load scenes, use ON/OFF to toggle between RGB and dynamic mask videos.
Abstract
Moving object segmentation is a crucial task for achieving a high-level understanding of visual scenes and has numerous downstream applications. Humans can effortlessly segment moving objects in videos. Previous work has largely relied on optical flow to provide motion cues; however, this approach often results in imperfect predictions due to challenges such as partial motion, complex deformations, motion blur and background distractions. We propose a novel approach for moving object segmentation that combines long-range trajectory motion cues with DINO-based semantic features and leverages SAM2 for pixel-level mask densification through an iterative prompting strategy. Our model employs Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion while integrating semantic support. Extensive testing on diverse datasets demonstrates state-of-the-art performance, excelling in challenging scenarios and fine-grained segmentation of multiple objects.
Overview
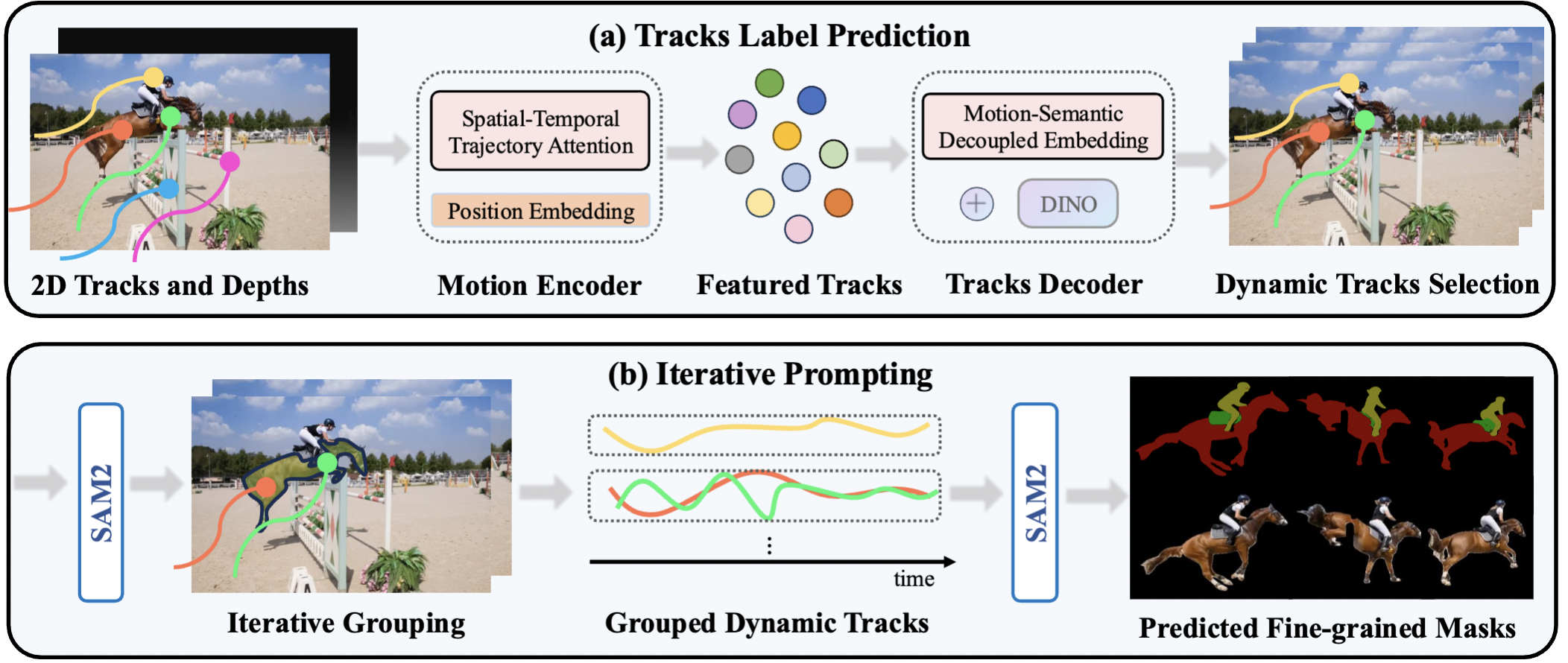
We take 2D tracks and depth maps generated by off-the-shelf models as input, which are then processed by a motion encoder to capture motion patterns, producing featured tracks. Next, we use tracks decoder that integrates DINO feature to decode the featured tracks by decoupling motion and semantic information and ultimately obtain the dynamic trajectories(a). Finally, using SAM2, we group dynamic tracks belonging to the same object and generate fine-grained moving object masks(b).
Why DINO feature?
We observed that in highly challenging scenes, such as those with drastic camera movement or rapid object motion, relying solely on motion information is insufficient. In this example, without DINO feature information, the model incorrectly classifies the stationary road surface as dynamic, despite the fact that the road lacks the ability to move. In the following video, the results in the first row do not include the DINO feature, and the results in the second row are our complete model.
Why Motion-Semantic Decoupled Embedding?
Simply incorporating DINO as an input during the motion encoding stage causes the model to rely heavily on semantic information, often leading it to assume that objects of the same type share the same motion state. In the following video, the results in the first row do not include our Motion-Semantic Decoupled Embedding, and the results in the second row are our complete model.
More Visual Results
Given the 2D long-range tracks of random samples, our model can determine the motion state of each track. And then we group and use the dynamic tracks as different prompt for SAM2. This video shows a non-cherry picked result for DAVIS2016-moving :)
More Visual Results of In-the-wild Data.
Our model is trained on synthetic and real datasets and has strong generalization performance. We show some visual results of our model on in-the-wild data:
Limitation Discussion.
During testing, we identified several limitations of our approach, which we believe can offer valuable insights. We discuss these limitations in the paper and leave addressing these fundamental directions for future work.
Related links
We recognize that a few concurrent works address similar problems to ours. We encourage you to check them out:
RoMo: Robust Motion Segmentation Improves Structure from Motion, and
Learning segmentation from point trajectories
Citation
If you use this work or find it helpful, please consider citing: (bibtex)
@InProceedings{Huang_2025_CVPR,
author = {Huang, Nan and Zheng, Wenzhao and Xu, Chenfeng and Keutzer, Kurt and Zhang, Shanghang and Kanazawa, Angjoo and Wang, Qianqian},
title = {Segment Any Motion in Videos},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},
month = {June},
year = {2025},
pages = {3406-3416}
}
Credit: The design of this project page references the project pages of NeRF and LERF.